
Measuring Awareness, Adoption & Trust for EVEE — JPMorgan Chase's Call-Center AI Assistant
How early discovery research on the pilot that became EVEE Intelligent Q&A instrumented the path from surfacing information to acting on it. What it took to scale AI maturity reliably leading to firm wide impact.
450+
Use cases and lessons learned (2025)
200,000
Employees onboarded within first 8 months of launch
30%
Reduction in call resolution times.
EVEE Intelligent Q&A is now a publicly documented JPMorgan Chase production system (see References). This case study covers the early-stage discovery research behind it. Specifics generalized per NDA.
Overview
JPMorgan Chase's Digital Customer Experience (DCE) team was building an LLM-based assistant for call specialists handling dispute, fraud, and transaction inquiries. The pilot has since scaled into EVEE Intelligent Q&A, now publicly reported as a production gen-AI tool deployed across JPMC's call centers. Its job was to surface and suggest the right guidance in real time, inside one of the most regulated, highest-stakes support environments in the company.
I led the research that evaluated how the assistant was actually performing inside its pilot. The research was not as a usability checkup on a prototype, but as the instrument that told the organization whether it had earned the right to advance the AI's capability. The study measured three things deliberately: did specialists know the AI was there (awareness), did they use it (adoption), and did they trust it enough to rely on it (trust). Those three measures are what make AI maturity scale consistently instead of by leap of faith.
Context
I was brought into the MLIO product space, which owned the machine learning and AI housing for JPMC. This was a historically high UXR churn environment with few established user experience KPIs. We had roughly eight scrum teams under a single product owner, with an area product owner on each pillar. A prior discovery-wall and opportunity-solution-tree process had surfaced a gap: we knew very little about how our guidance ML/AI models were actually performing in the field.
At the time, a 200-specialist pilot was testing a prototype native application that delivered real-time curated guidance during live calls. We immediately received reports that agent usage of the initial capability was at an all time low. The pilot was running, but blind and we had a product in specialists' hands and no rigorous read on whether it was working, why, or what it would take to push it further.
Team: UX Research Lead (me) & UX Design Lead
The strategic frame: a maturity ladder, not a feature test
The assistant was climbing a capability ladder, and each rung carries a different relationship between the human and the AI:
Stage 1 — Surface. The AI displays relevant information. The specialist does all the deciding.
Stage 2 — Suggest. The AI actively recommends an action or answer. The specialist evaluates and chooses.
Stage 3 — Assist (act with approval). The AI proposes to act and executes on the specialist's approval. The specialist supervises rather than drives.
The pilot lived in Stages 1 and 2, with a clear ambition to reach Stage 3. My thesis was that you cannot advance a stage reliably without measuring awareness, adoption, and trust at the stage you're on because each gates the next:
Awareness gates everything. If specialists don't know a capability exists in their workflow, it's invisible, and every downstream metric reads as zero. An awareness gap is routinely misdiagnosed as "the AI isn't useful."
Adoption gates trust data. You can't measure trust in something nobody uses. Awareness without adoption means the capability is seen but not integrated.
Trust gates the climb. Surfacing tolerates low trust — the human verifies everything. Suggesting needs moderate trust — the human weighs the recommendation. Acting-with-approval demands high, calibrated trust. Push to Stage 3 before trust is demonstrated and specialists either rubber-stamp blindly (a risk event waiting to happen) or reject reflexively (capability paid for and wasted).
Measuring all three at each stage is what turns "are we ready to advance?" from an executive gut call into an evidence-gated decision and gives a repeatable instrument you can re-run at every stage and every product, so AI maturity scales the same way every time instead of being relearned per team.
The study
A mixed-methods evaluation with 12 participants, sampled across call-volume tiers, tenure, performance, onshore/offshore status, and mixed ability so findings weren't an artifact of one kind of specialist. Five components, each pulling on a different part of the awareness / adoption / trust picture:
Initial interview and job shadow. Casual rapport-building to understand each specialist's real working conditions before observing them.
Wizard-of-Oz call scenarios with discrete trials. Specialists worked real recorded calls against a Figma prototype I controlled remotely, paired deliberately to key opportunity scenario types which let me observe authentic in-call behavior without a fully built system.
Participatory design. Each specialist was invited to add one feature to their work experience which allowed us to surface needs the prototype hadn't anticipated, and deliberately not limited to the prototype itself.
A/B test with embedded discrete trials. Two prototype variants tested for preference, plus probes on what specialists thought specific features meant or did which facilitated a direct read on comprehension and trust.
Final interview. Closing reflections, and a formal channel for the team to follow up with specialists.
This was scoped intentionally as more than a prototype study with specialists empowered to raise any solution, not just prototype improvements.
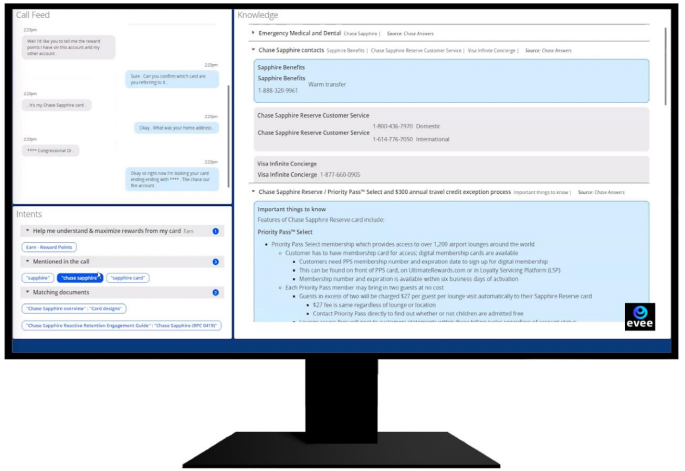
What we found
Awareness was the binding constraint. 11 of 12 specialists didn't know to look at the prototype for guidance unless they specifically went searching for it. Read through the maturity frame, this is a Stage 1 failure: the assistant was effectively invisible at the moment of need, often due to the current prototype burying the answer too deep in its initial response causing the agent to give up and lose trust. The recommendation that followed was suggested surface guidance directly in the core workflow rather than in a standalone native application. This was the single most important strategic output, because no later stage works until awareness is solved. (EVEE's now-public form integrates directly into specialists' existing tools.)
Comprehension is a trust prerequisite. 9 of 12 specialists didn't know what "Call Intent" meant; 5 suggested "Call Reason." We renamed it. Small on its face, but at Stage 2 a specialist won't act on a suggestion they don't understand or are confident about. Language is part of the trust surface and not just discoverability.
Information density calibrates the suggest stage. The A/B work probed whether more specific information or more quantity of information served specialists better, and how much was too much on a display already constrained to roughly 600×600 by competing applications on agents' screens. Over-surfacing erodes both usability and trust; calibrating it is how Stage 2 stays credible.
Operational reality shapes what's measurable. Training the models takes time and can't be done in natural work contexts. Constraints like average-handle-time (AHT) requirements have to be lifted from pilot populations, or the measurement environment distorts the behavior you're trying to read. I had to advocate for the transition away from traditional AHT requirements for agents until we could effectively provide reliably helpful suggestions.
Tactically, several issues were caught and solved live: a native-app wrapping problem under condensed layouts was identified and fixed in collaboration with the Design Lead during the study itself.
Reflection
What I learned. Coming into an already established AI development environment with trust issues was a firehose moment. It wasn’t just about building a product. It was literally a gut check on how important trust and noticeability is to building solutions. If you move too fast or your solution is ineffective, even your own employees will bury your product. These agents were legitimately worried about their performance KPIs including factors like average handle time and didn’t want to gamble their performance on a tool that wasn’t production ready yet. In hindsight, this was common sense once you have experience building Gen AI and didn’t need a study to explain. Without trust and noticeability, all your adoption or training KPIs are dust. Without the safety to train it, people wont take risks.
What I'd do differently. Although I captured these qualitative learnings and it led me to stand up quantitative KPIs embedded within the pilot prototype, I would have stood up quantitative baselines right after I landed to give me a grounded starting point. This included tracking for discovery rate, source data inspection rates, return visit rates, time to first meaningful interaction, surface to decision rates, stated confidence, and mention rate in help requests within the internal pilot communication channels. I could have triangulated all of that early on to help inform the study scope in advance and track impact rolling into next steps.
Where EVEE is today
The prototype I researched in pilot has since scaled into EVEE Intelligent Q&A, publicly reported as a production gen-AI assistant deployed across JPMorgan Chase's call centers. It’s integrated into specialists' existing tools, drawing on policy documents and transaction histories, and credited with faster resolution times and improved employee and customer satisfaction.
The strategy this research was built to instrument is now visible in JPMC's public roadmap. The firm's publicly stated progression including back-office efficiency first, then front-office functions, then more advanced agents capable of human-like reasoning is the same surface → suggest → assist ladder. Leadership has publicly emphasized the exact levers this study measured: clear KPIs, test-and-control experimentation, and the work required to drive adoption. Leadership has named AI hallucination, the trust problem, as the central challenge of moving AI toward higher-stakes, customer-facing decisions. Measuring awareness, adoption, and trust at each stage is how that progression stays reliable instead of risky.
References
JPMorgan Chase's Gen AI implementation: 450 use cases and lessons learned — Tearsheet, May 2025
Case Study: How JPMorgan Chase is Revolutionizing Banking Through AI — AI Expert Network, June 2025
AI Research — JPMorgan Chase (official)